

会話AIの進化:機械翻訳からLLM、そして未来へ?機械翻訳、オープンソースLLM、そして課題と展望
会話AIの進化とLLMの現在地を解説! GoogleやFacebookの研究からChatGPT登場、オープンソースLLMの躍進までを網羅。翻訳技術の革新、LLM開発競争の激化、そして課題まで、AI技術の最前線をコンパクトにお届けします。
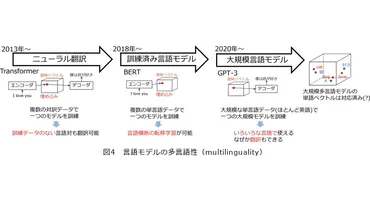
💡 機械翻訳は、統計的機械翻訳の発展により、飛躍的な翻訳精度向上を遂げた。
💡 LLM開発競争は激化し、MetaのLlama 2など、オープンソースモデルが台頭。
💡 LLMは情報検索、クリエイティブ制作など多岐にわたる分野で活用され、課題も存在する。
本日は、会話AIの技術革新について深掘りしていきます。
まずは、その黎明期から見ていきましょう。
会話AIの黎明期:機械翻訳とTransformerの誕生
会話AI進歩の鍵は?Googleの突破口とは?
統計的機械翻訳とseq2seq技術です。
会話AIの黎明期から現在までの技術的進歩を簡潔にまとめています。
✅ NTTコミュニケーション科学基礎研究所の永田昌明上席特別研究員は、日英特許対訳コーパスを用いた機械翻訳の研究を進めており、特許関連文書の翻訳精度向上を目指している。
✅ 特許翻訳の課題として長文の翻訳精度低下があり、世界最高精度の単語対応技術を用いて精度向上や誤訳指摘システムの開発を目指すとともに、大規模言語モデル(LLM)を活用した翻訳の研究も行っている。
✅ LLMを活用した機械翻訳は、多言語話者に翻訳を依頼するようなもので、従来のニューラル翻訳とは異なるアプローチで翻訳が行われる。
さらに読む ⇒技術ジャーナル出典/画像元: https://journal.ntt.co.jp/article/24997長文翻訳の精度向上や、LLMによる新たな翻訳アプローチは興味深いですね。
大規模言語モデル(LLM)が登場する以前から、人間と会話できるAIの開発は進められていました。
2015年頃には、Googleがseq2seq技術を用いた会話エンジンを発表し、Facebook AI Research(現Foundamental AI Research)は2017年に対話モデル「ParlAI」を公開、2018年にはWikipediaの情報を用いたデータセット「WizardofWikipedia」を公開しています。
これらの技術は、現在の会話AIの基盤となっています。
機械翻訳は、従来の自然言語処理が抱えていた「越えられない壁」を、Googleの「統計的機械翻訳」が打破しました。
この技術は、意味の理解を前提とせず、文脈に基づいた単語の出現確率を予測することで翻訳を実現し、現在LLMの基盤となっています。
LLMによる機械翻訳は、日本語と英語の対を学習し、日本語の後にスラッシュを付加することで英語を生成するという形で実現されています。
すごい!機械翻訳って、こんなに進化してたんだ。seq2seqとか統計的機械翻訳って、難しいけど、すごく役に立ちそうですね!
LLM開発競争の激化とオープンソースモデルの台頭
ChatGPT対抗馬続々!オープンソースLLMの躍進、鍵は?
Vicunaなど、OpenAI API不要の高性能LLM登場。
LLM開発競争の激化が、活発な技術革新を生み出していることがわかります。
公開日:2023/07/19

✅ Metaが、研究および商用利用向けに無償で提供するオープンソースの次世代大規模言語モデル「Llama 2」を発表しました。
✅ Llama 2は、パラメータ数が70億、130億、700億の事前学習モデルと会話に特化したファインチューニングモデルがあり、学習データとコンテクスト長がLlama 1から増加しています。
✅ Microsoftが優先パートナーとなり、Azure AIモデルカタログで利用可能になったほか、Windows上でのローカル動作の最適化も進められており、AWSやHugging Faceでも提供されます。
さらに読む ⇒出典/画像元: https://pc.watch.impress.co.jp/docs/news/1517320.htmlオープンソースモデルの台頭は、誰もがAI技術を利用できる可能性を示唆していますね。
ChatGPTの登場によりLLMへの関心が高まり、MicrosoftがOpenAIに巨額の投資を行ったことで、LLM開発競争が激化しています。
MetaはLLaMAを発表し、ChatGPTに対抗できる可能性を示しました。
LLaMAを基盤とした、AlpacaやVicunaといったオープンソースモデルも登場し、ChatGPTと同等の性能を持つことを目指しています。
特にVicunaは、OpenAI APIを利用せずにChatGPT並みの性能を達成することを目指しており、その技術的優位性を示しています。
また、DatabricksはDolly-v2というLLMを公開、Stability.aiはStableLMを発表するなど、様々なLLMが登場しています。
オープンソースLLMの台頭は、AI技術の民主化を促進し、より多くの人々がLLMを利用できるようになることを意味します。
Llama 2のようなオープンソースモデルが、無償で利用できるのは素晴らしい。AI技術が広まることで、私たちの生活も豊かになりそうですね。
LLMが抱える課題と将来展望
LLMの進化を阻む課題とは?
バイアス、プライバシー、正確性、コストなど。
LLMの定義や活用事例、課題が簡潔にまとめられています。
公開日:2024/12/02
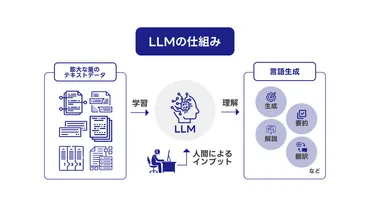
✅ LLM(大規模言語モデル)について、その定義や重要性、関連技術との違い、活用事例、課題と対策、今後の展望を解説しています。
✅ LLMは、膨大なテキストデータを学習し、人間のような自然な言語生成や理解を実現する深層学習モデルであり、ChatGPTなどのモデルが活用されています。
✅ LLMは情報検索、クリエイティブ制作、教育、業務効率化など様々な分野で活用されており、出力の制御、倫理性の向上などの課題に対応しながら、今後の発展が期待されています。
さらに読む ⇒株式会社ブレインパッド()|データ活用推進パートナー|データ活用の促進を通じて持続可能な未来をつくる出典/画像元: https://www.brainpad.co.jp/doors/contents/01_about_llm/LLMには、倫理的な課題や計算コストなど、克服すべき問題がまだ多いのですね。
LLMの開発は目覚ましい進歩を遂げていますが、学習データのバイアス、個人情報やプライバシーの問題、情報の正確性、インプット言語による精度差、そして莫大な計算コストといった課題も存在します。
AIは翻訳という意識を持たずに、確率的な予測によって文章を生成しているため、その出力結果の解釈には注意が必要です。
LLMは、これらの課題を克服しながら、今後ますます進化していくことが期待されます。
LLMって、すごい可能性を秘めているけど、課題もあるんですね。AIがどんな作品を生み出すのか、すごく楽しみだし、自分でも実験してみたい。
本日の記事では、会話AIの進化と課題についてご紹介しました。
今後の更なる発展に期待したいですね。
💡 機械翻訳は、統計的機械翻訳の登場で精度が向上し、LLMの開発に繋がった。
💡 LLM開発競争は激化し、オープンソースモデルの台頭でAI技術の民主化が進んでいる。
💡 LLMは様々な分野で活用されているが、バイアス、プライバシー、正確性などの課題も存在する。